LLVM GSoC '20 Hot/Cold Splitting
Ruijie Fang <ruijief@princeton.edu>
Note: This page is compiled by LyX into XHTML format; it works best in Firefox, as the footnotes are properly displayed. When you encounter images, click to enlarge them.
Mentors
Aditya Kumar, Rodrigo Rocha
Synopsis
The objective of this project is to find ways to improve the outlining ability of the hot/cold splitting optimization pass in the LLVM compiler on two real-world workloads: qemu (both userspace and full-system emulation) and Firefox. In terms of deliverable code, my contribution to this project is a series of small patches to the Hot/Cold Splitting pass that added section splitting, longjmp outlining, EH outlining capabilities and a bugfix in LLVM's basic block extractor (CodeExtractor). In addition to contributing code, I also collected benchmark data on Firefox and qemu codebases to test different ideas to improve hot/cold splitting's outlining ability, and wrote scripts to automate the testing/benchmarking workflow. During the three-month process, I met with Aditya and Rodrigo weekly and had routine conversations via Discord for discussion. This report is a comprehensive summary of my work performed this summer during GSoC'20 and relevant ideas discussed between me and my mentors.
Contributions
We found that when applying PGO+HCS to compile Firefox results in a 5% speedup in Firefox performance benchmarks (talos-test perf-reftests):
|
|
Time (mean)
|
Time (median)
|
|
-O2 Baseline
|
1015.8s
|
1015.0s
|
|
-O2 PGO+Vanilla HCS
|
961.3s
|
961.0s
|
We also found that Hot/Cold Splitting can reduce the code size of Firefox by 2%:
|
|
Opt Level
|
Size (incl. dynamic libraries)
|
|
Vanilla HCS
|
-O3
|
2.247788640 GB
|
|
baseline
|
-O3
|
2.299546240 GB
|
Code Contributions.
My code contribution comes in the form of a series of patches on LLVM's Phabricator:
- D69257 (Outlining noreturn functions unless a longjmp): Add capability to outline noreturning functions except longjmp intrinsics.
- D85331 (Add options for splitting cold functions into separate section): Add section-splitting capability: Put cold functions into a separate section into compiled binary.
- D85628 (Add command line option for supplying cold function names via user-input): Add command line option to take in a list of cold function names.
- D84468 (Add splitting delta option to split more small blocks) Add option to add a user-defined “delta” value to boost the cost model's benefit score.
- D86832 (Add support for outlining Itanium EH blocks by hoisting calls to eh.typeid.for intrinsic) Support outlining Itanium-style exception handling regions.
Additional Contributions.
Additional contributions come in the form of scripts that automate the process of benchmarking different hot/cold splitting implementations and collecting the resultant benchmark data. The scripts are listed below:
Project Timeline
Initial Plan: Benchmarking qemu.
We started our work by collecting benchmark information on qemu userspace and qemu wholesystem benchmarks. Userspace qemu (whose binary size is smaller) can be used to run individual binaries, whereas wholeystem qemu (whose binary size is larger) is used to simulate an entire virtual machine, for running payloads such as operating system images. Instrumenting userspace qemu proved to be relatively problematic, due to qemu's nature as a machine code translator: LLVM instrumentation works by injecting extra code, (via the compiler-rt infrastructure) which writes instrumentation data to disk, into the program's exit handler. However, upon receiving an exit signal, the qemu userspace emulator will immediately translate and feed the appropriate exception instruction into the host CPU, thereby executing the emulated program's exit handlers rather than qemu's own exit handlers. Therefore, to appropriately collect instrumentation data, we had to modify the qemu source code to call qemu's own exit handlers.
For userspace qemu benchmark, we utilized userspace qemu and the system's default clang/clang++ to compile postgresql, and measured the overall compile time. For wholesystem qemu, we measured the time spent booting up Ubuntu 16.04 and running several of byte-unixbench benchmarks using x86_64 wholesystem qemu.
Insignificant results on qemu made us switch to benchmarking firefox.
However, as seen in the results section, the benefits of hot/cold splitting on qemu was not obvious, and most of the experiments yielded no gains beyond noise. We think the reason is as follows:
1. The size of qemu binaries are small (~15MB for userspace and ~50MB for x86_64 wholesystem binaries)
2. The computer on which we ran the benchmarks has an Intel Xeon E5-1607 CPU, 32GB ECC RAM, and 10MiB L3 cache. The large cache sizes and the powerfulness of the CPU rendered the gains produced by an icache optimization like Hot/Cold Splitting insignificant.
3. qemu is written in C; whereas, hot/cold splitting should be more effective for C++, where the code base is more complex and leaves room for outlining optimizations.
As such, we decided to switch to benchmarking firefox (via PGO-compiling Firefox's repository mozilla-central); the Firefox production binary size (with dynamic libraries included) is ~2-3GBytes, depending on the compiler flag and optimizations used, together with the amount of C++ code contained in Firefox makes it a nice candidate for our benchmarks. Our methodology for benchmarking firefox is to compile Firefox using PGO+Hot/Cold Splitting, then run a performance benchmark using the “talos-test perf-reftest” testsuite, which is the same set of tests we use to obtain instrumentation data.
Improvement Idea 1: Hot/Cold Splitting + Inliner.
The first improvement idea for applying Hot/Cold splitting to Firefox was suggested by Rodrigo. We devised an HCS implementation that runs early in the new PassManager's PGO optimization pipeline, immediately before the stock ModuleInliner pass: https://github.com/ruijiefang/llvm-hcs/tree/arcpatch-D57265. Thus, we outline code every time before we inline. As seen in the results section, this approach greatly increased the number of cold blocks detected and split, at the expense of blowing up the code size by more than 5%. However, no significant performance benefits were observed. Since this approach causes an increase in code size at the expense of outlining more blocks, and the modifications to the source code was rather involved, we did not propose it as a patch to Phabricator. Instead, it lives as a branch on our own LLVM fork: https://github.com/ruijiefang/llvm-hcs/tree/arcpatch-D57265.
Improvement Idea 2: Adding a Delta Option.
The second improvement idea stems from our analysis of the behavior of the cost model when compiling qemu with hot/cold splitting. By making a histogram of the hot/cold split cost model on qemu blocks, we found there are a large number of blocks with negative benefit-penalty differences, but the difference themselves are relatively small:
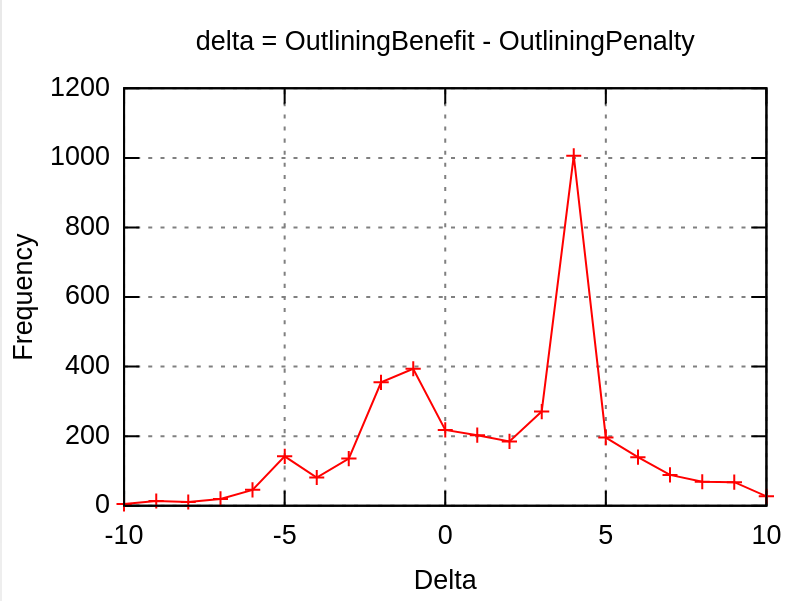
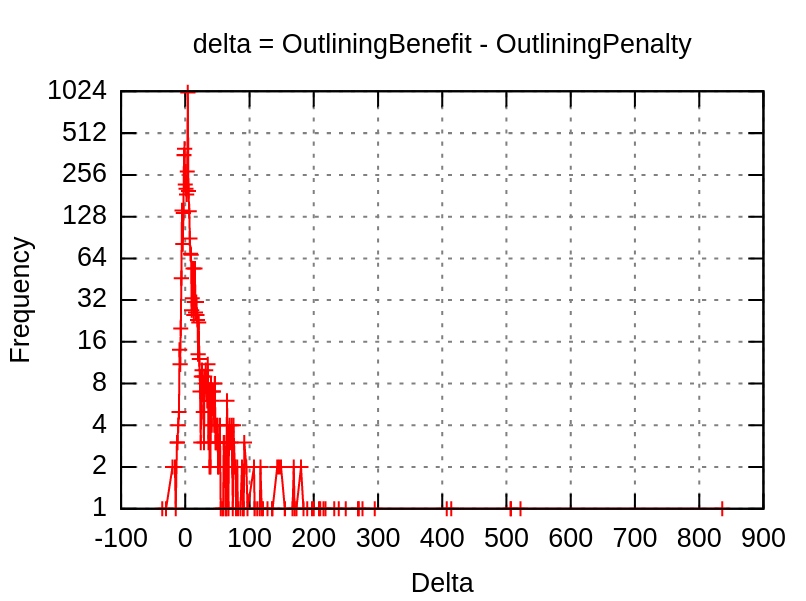
Therefore, we experimented with whether splitting these blocks with negative benefit-penalty differences in range
where
is a small value between -1 and -5. The result, as outlined in the benchmark data section, is while there is a slight gain in performance data in qemu benchmarks, there is a code size increase. Vedant Kumar later pointed us towards an earlier patch he implemented, D59715, which adds more granular input size checking to the cost model for computing penalties. The proposed changes in D59715 is confirmed to both perform well (with negligible effect on performance and a reduction in code size) on Firefox benchmarks. Our modification is proposed as a patch (
https://reviews.llvm.org/D84468).
Improvement Idea 3: Put cold functions in a different section.
Another improvement idea we tried is to place cold functions into a different section in order to further increase instruction cache affinity for hot functions. This is implemented in patch D69257 (
https://reviews.llvm.org/D69257), and thereafter merged into LLVM trunk. Together with LLVM's newly added LLVM machine function splitter optimization pass, the modification is shown to be benefitial in terms of reducing the number of pagefaults.
Improvement Idea 4: Improved static analysis with longjmp and EH outlining.
As a first improvement, we merged Aditya's patch D69257 (https://reviews.llvm.org/D69257), which adds capability for outlining noreturn functions unless a longjmp. Next, we proceeded to work on outlining Itanium-style exception handling blocks. Itanium-style EH handling in LLVM follows roughly the following structure:
invoke-***
|
lpad-***
|
catch.dispatch
| |
catch |
| |
catch.fallthrough
|
resume
With our implementation of EH outlining, we are able to outline most non-nested try/catch regions in C++ code. The idea is to hoist the problematic calls to eh.typeid.for to some earlier entry block before the region dominated by the landing pad block, and split the block containing the landingpad instruction into a block containing only the landingpad instruction and possibly some phi-nodes, and a block containing the rest of the EH entry block, terminated by an unconditional branch to catch.dispatch. This implementation supports some partial outlining of nested EH regions as well.
An example of try/catch outlining is as follows. We will focus on the following C++ code:
int main()
{
int i = 3;
try {
if (i == 3) throw i;
} catch (int e) {
exit(i);
} catch (char c) {
exit(2);
} catch (long d) {
exit(4);
} catch (string s) {
exit(5);
}
return 0;
}
The above code produces the following (unoptimized) IR CFG:
Our EH outliner implementation hoists the call to eh.typeid.for contained in the and blocks into block, splits the landingpad block in half, and feeds the transformed region starting from the direct successor of the new lpad block into the OutliningRegion outliner. The result is as follows, with two regions extracted:
The difficulties of outlining are as follows:
- We cannot extract the block containing the invoke, otherwise we'll potentially extract the hot branch as well;
- We cannot extract the entire landing pad block, since the first instruction after the unwind edge into the lpad block must be the landingpad instruction.
- It seems possible to simply split the lpad block into two from the first instruction, and then outling starting from there; this is analogous to issue #4, which we outline below;
- The block at catch.dispatch contains potentially a series of calls to the eh.typeid.for intrinsic to use function-specific type information to match if the catch call can go through. As such, CodeExtractor cannot extract these calls (See detailed discussion and example in https://bugs.llvm.org/show_bug.cgi?id=39545). Making typeid.for outlining-friendly seems in general a difficult task, as the proposed patch in 39545 uses an entirely new pass to do so.
- What remains is the idea of extracting the typeid.for intrinsic calls to further up in the control flow graph, and since we have rather normal control flow, we can do so safely and store the resultant values in some variable. However, consider the following example of nested throws:
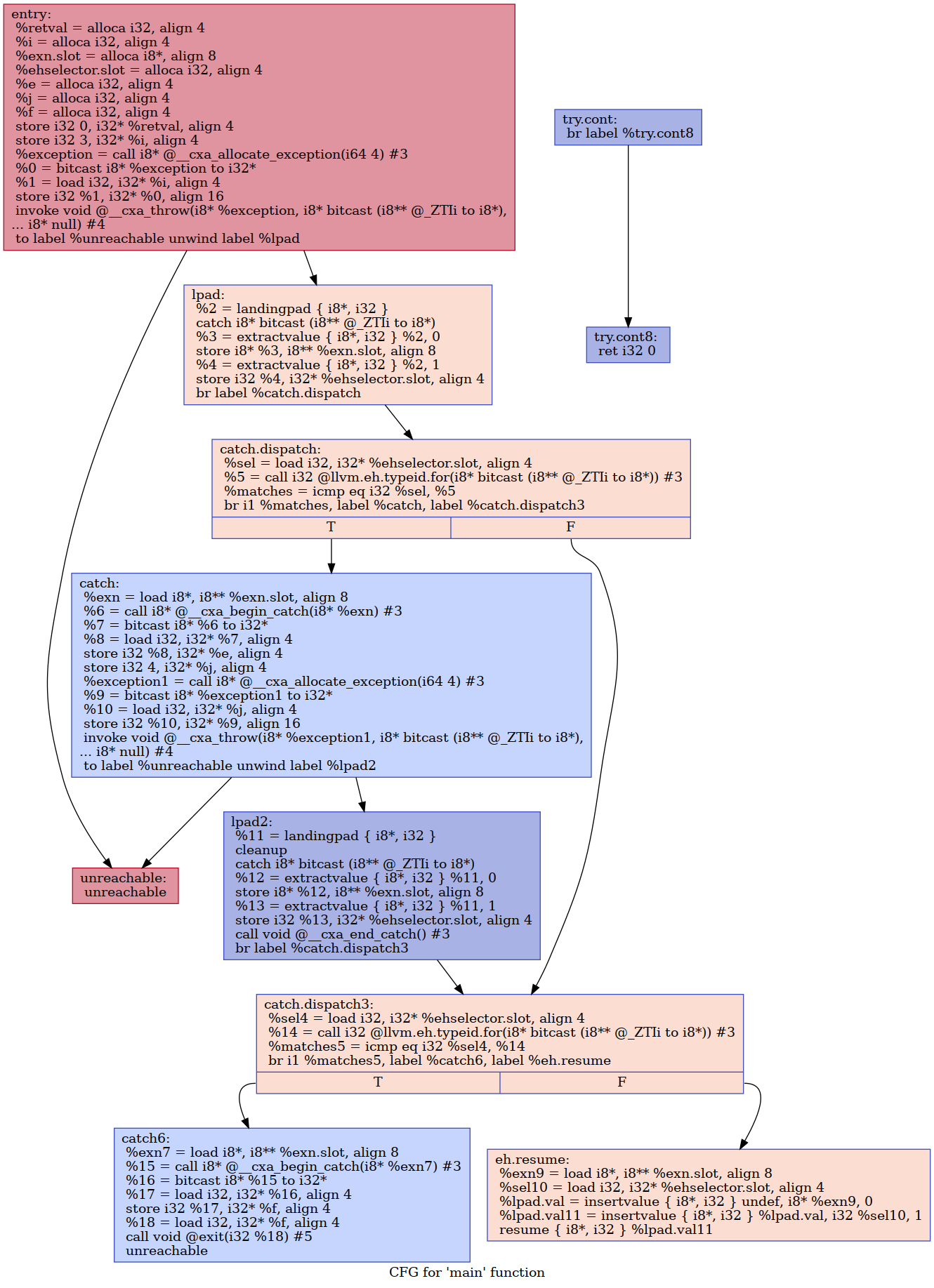
Since there are multiple catch.dispatch blocks, we cannot simply extract calls to eh.typeid.for from them to an arbitrary block that precedes them. On hindsight, it seems like we can just extract the call instructions to the successor block (between itself and landingpad block) to catch.dispatch. However, doing so is potentially unsafe, since the fallthrough branch of a try block in an outer nesting directly goes into the catch.dispatch block in the inner nesting, which means we cannot use the eh.typeid.for values unless we insert a phi node. Expanding on our previous example, the following hoisted CFG needs a phi-node inserted in catch.dispatch3:
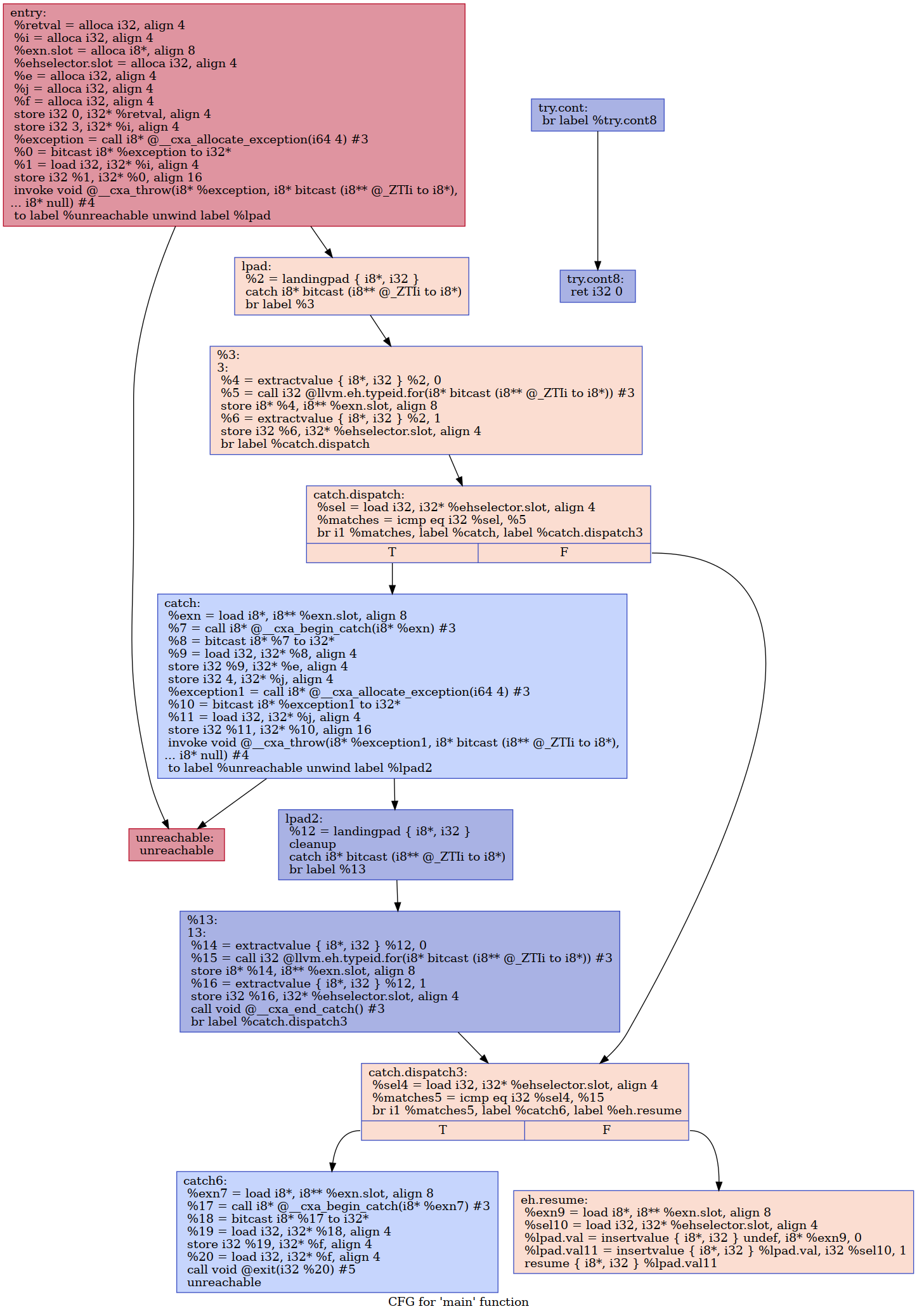
A possible solution is to extract these call instructions to the highest post-landingpad block that dominates them. This is the "safe" strategy we currently implement: https://github.com/ruijiefang/llvm-hcs/tree/eh-prepare. However, there are still complex cases of nested throws we cannot fully outline, mainly because the current implementation of OutliningRegion does not guarantee to extract maximal SESE regions. A good example is the CFG example provided above.
Empirical data collected on compilation of Firefox suggests the EH outlining implementation is beneficial; in -Os compilation experiments, enabling EH outling leads to both reduced code size as well as an increased number of detected cold blocks. For detailed data, see the results section.
Improvement Idea 5: Using user-supplied cold functions list to outline standard library functions.
In some cases, the user might want to specify which functions are explicitly cold. We contributed a patch that adds two options, cold-functions-list and cold-functions-file that enables the user to supply lists of cold function names to hot/cold splitting. The optimization pass will then mark any function encountered with the same name as cold.
The patch aims to solve the issue of outlining cold paths induced by C++ static initializers. For instance, consider the following C++ code
struct foo {
[[gnu::weak]] foo() noexcept;
[[gnu::weak]] ~foo();
};
void go() {
static foo f;
}
void go_leaky() {
static foo& f = *new foo();
}
The static initializer inside function compiles down to calls to standard library routines . The idea is that the user can supply these functions as an option to hot/cold splitting in order to benefit from outlining them. However, the patch is still in review since many are unsure if the user-supplied cold functions approach a good idea.
Results
firefox, talos-test perf-reftest (-O2 6 runs, performance).
|
|
Time (mean)
|
Time (median)
|
Regions Detected
|
Regions Split
|
|
-O2 Baseline
|
1015.8s
|
1015.0s
|
|
|
|
-O2 PGO+Vanilla HCS
|
961.3s
|
961.0s
|
152048
|
69444
|
|
-O2 PGO+Inliner HCS
|
959.444s
|
959.0s
|
157166
|
74166
|
|
-O2 D59715
|
964.447s
|
953.472s
|
|
|
Summary. In the performance benchmark shown above, we see that all three hot/cold splitting variants achieved a ~6% speedup over the -O2 baseline. In addition, the HCS+Inliner implementation detected and split more regions, due to its position in the early stage of the optimization pipeline, before inlining.
firefox, code size.
Comparing -Os baseline HCS with our EH-outliner-enabled HCS shows an increase in number of regions detected as well as a reduction in code size:
|
|
Opt Level
|
Size (incl. dynamic libraries)
|
Regions Detected/Regions Split
|
|
delta=0 HCS
|
-Os
|
2.188262032 GB
|
142678/62985
|
|
EH outlining HCS
|
-Os
|
2.187481424GB
|
142081/62982
|
Comparing code size across different HCS delta values and the D59715 patch suggests D59715 performs best in terms of code size reduction:
|
|
Opt Level
|
Size (incl. dynamic libraries)
|
|
D59715
|
-Os
|
2.184796592 GB
|
|
delta=5 HCS
|
-Os
|
2.206931464 GB
|
|
delta=-2 HCS
|
-O3
|
2.270277648 GB
|
|
delta=0 HCS
|
-O3
|
2.247788640 GB
|
|
D59715
|
-O3
|
2.243288440 GB
|
|
delta=2 HCS
|
-O3
|
2.259242024 GB
|
|
delta=5 HCS
|
-O3
|
2.270277648 GB
|
|
baseline
|
-O3
|
2.299546240 GB
|
Summary. It is worthy of mentioning that although (as shown below) splitting blocks with the delta value “boost” might lead to potential performance gains, it leads to a code size blowup in general. On the other hand, patch D59715 leads to a consistent code size reduction without performance regressions. It is useful to note that due to differences in the transformations required in different optimization levels, the number of regions detected/regions split on changes as well.
qemu-x86_64-userspace, clang compilation of postgresql.
|
|
Time (mean across 3 runs)
|
|
-O2 HCS-enabled, delta=0
|
46m4.717s (user) / 12m29.95s (real)
|
|
-O2 HCS-enabled, delta=-5
|
45m25s (real) / 12m25s (user)
|
|
-O2 PGO baseline
|
45m39.76s (real) / 12m23.28s (user)
|
|
-O2 non-PGO baseline
|
53m47.5s (user) / 14m40.3s (real)
|
Regions split: 4332
Regions extracted: 2911
qemu-x86_64-wholesystem, ubuntu 16.04 startup+Byte-Unixbench benchmarks.
This benchmark measures the time spent starting up ubuntu 16.04 and running several byte-unixbench benchmarks: pipe, spawn, context1, syscall, dhry2, each for 50,000 iterations.
|
|
Time (mean across 6 runs)
|
icache miss rate
|
branch miss rate
|
|
-O2 Vanilla HCS
|
38.3379s (stddev: )
|
1.952%
|
1.692%
|
|
-O2 HCS+Cold Sections
|
38.4339s (stddev: )
|
1.936%
|
3.118%
|
|
-O2 PGO baseline
|
38.66s (stddev: )
|
1.912%
|
3.150%
|
Summary. No significant gains were observed between an implementation with hot/cold splitting applied versus an implementation with hot/cold splitting disabled. As mentioned in previous paragraphs, we think this is partly due to qemu's nature as an instruction translator, as well as its limitations in code size as well as programming language. However, we can see that PGO-enabled compilation in general is helpful.
Epilogue
The end of my GSoC project marks not an end, but a new beginning. I look forward to continuing my work in the following directions with my two mentors.
Future work.
Based on my discussion with my mentor, we plan to carry our work in two directions in the future:
- Experiment on a “pipeline” of passes built for outlining: With the newly added machine function splitter pass, hot/cold splitting can be done both in the mid-end and backend. Future work in this direction, as proposed by my mentors, will focus on combining HCS+Inliner+MergeFunctions or HCS+EH Outlining+MergeFunctions for optimizing code size (in the first case, we have shown that scheduling HCS before inliner increases the number of basic blocks split; MergeFunctions can be then applied to merge similar cold functions; in the latter case, experience suggests that many catch blocks have similar structure, and the extracted catch blocks have a potential to be merged by the MergeFunctions pass). And finally, there might be additional gains by applying MachineFunctionSplitter after HotColdSplitting later in the pipeline.
- The detection of maximal SESE regions in hot/cold splitting pass. The current OutliningRegions implementation in Hot/Cold Splitting does not detect maximal SESE/SEME regions surrounding a cold block, instead it detects a “safe” SESE region using the dominator/post-dominator tree. Although by default the RegionInfo pass in LLVM can be quadratic in worst-case time complexity, practical algorithms exist to detect maximal SESE regions. Work has already begun in this direction: I am in the process of implementing a maximal SESE region detection algorithm using the SESE program structure tree, and Rodrigo Rocha has a finished fork which implements maximal SEME detection using a SEME program structure tree. Both implementations work in linear-time and hence do not induce extra compilation overhead. Additional work can be done in this direction to apply these implementations to real-world workloads such as Firefox and see if any practical improvements over the existing implementation might be possible.
Acknowledgements.
First and foremost, I would like to thank my two wonderful mentors, Aditya Kumar and Rodrigo Rocha, for their kind mentoring and helpful discussions which happened over Discord each week. I would also like to thank Vedant Kumar, Snehasish Kumar, and other LLVM contributors who reviewed my patches and provided insights. Finally, I would like to thank Google Summer of Code for their generous support, and the LLVM compiler infrastructure community for providing me opportunity to work on such an interesting and enabling project.






